Klik på billedet for at se det i stort format.

Klik på billedet for at se det i stort format.
Ganske hurtigt endte vi med en kørende demo, der kunne afsende data fra en Internet opkoblet enhed, lade Microsoft Azure indsamle, processere, analysere disse data og endeligt at være istand til at visualisere de behandlede data på et web-baseret real-time dashboard.
Azure IoT Suite
Azure IoT Suite er en samling af teknologier der målretter sig Internet of Things enheder, og kommunikation imellem Azure og IoT enhederne.
Her et uddrag fra Microsoft Azure IoT Suite beskrivelsen:
- Get started quickly with preconfigured solutions
- Tailor preconfigured solutions to meet your needs
- Enhance the security of your IoT solutions
- Support a broad set of operating systems and protocols
- Easily connect millions of devices
- Analyze and visualize large quantities of operational data
- Integrate with your existing systems and applications
- Scale from proof of concept to broad deployment
Vi kan anbefale disse videoer, til hurtigt at danne sig et overblik over Azure IoT Suite teknologierne:

Link til indhold på azure.microsoft.com, klik på billedet for at se video

Link til indhold på azure.microsoft.com, klik på billedet for at se video
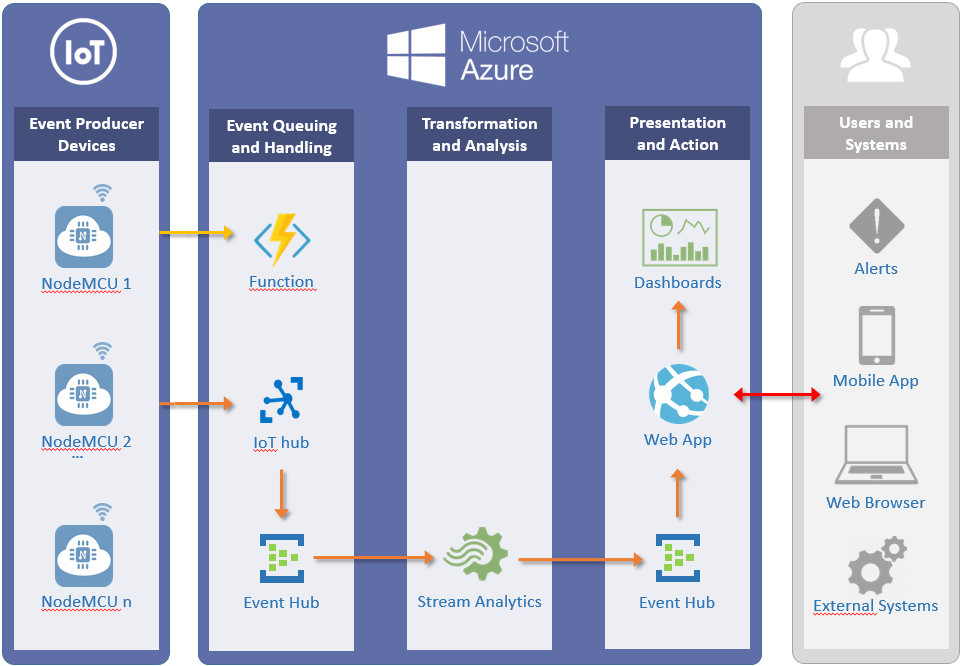
Gennemgang af demoen udfra system skemaet
Her følger en beskrivelse af demonstrationssystemet vi satte op. Start med at granske system skema billedet. Afsnittene herefter tager udgangspunkt i hvert af elementerne i dette billede fra venstre mod højre.
NodeMCU
Til eksperimentet har vi brugt det indlejrede-system NodeMCU. NodeMCU-enhederne udemærker sig ved at være meget små (ca. 5 x 3 cm), nemme at programmere (via Arduino IDE værktøjet) og har såvel indbyggede GPIO pins samt WiFi funktionalitet.
Der er kun anvendt en enkelt NodeMCU enhed, men man ville sagtens kunne bruge mange flere, f.eks. i et produktionsscenarie, op imod Microsoft Azure.
Denne guide beskriver hvordan du kan opsætte NodeMCU til at fungere op imod Azure IoT.
Azure Function
Som det første satte vi en Azure Function op, som en HTTP WebHook triggered funktion, dvs. en funktion der kan kaldes via et alment HTTP request ind imod funktionens dedikerede URL hos Azure med en række parametre. Dette viser hvordan en IoT enhed kan kalde ind på f.eks. en web service eller som her direkte ind på en Azure Function, og på den vis foranledige afviklingen af et tilpasset stykke forretningskode. Dette kunne eksempeltvis resultere i at en e-mail blev afsendt, at en særlig database række blev skrevet ned, eller at en fejllog-linie blev genereret, og meget andet.
Azure IoT Hub
NodeMCU-enheden er programmeret til at generere tilfældigt data hvert tiende sekund. Disse data bæres ind via en Azure IoT Hub. Dette endpoint fungerer som kontaktfladen imellem IoT enhederne og Azure skyen, og omvendt, også fra Azure til IoT enhederne (såkaldt bi-direktionel kommunikation). Azure IoT Hub’en skalerer automatisk op til mange millioner samtidige IoT enheder.
Eksempel på JSON data afsendt fra enheden til Azure:
{
"Dev":"nodemcu-hinnerup",
"Utc":"2016-10-15T22:29:33",
"Celsius":25.00, "Humidity":50.00, "hPa":1012, "Light":0,
"WiFi":1, "Mem":21416, "Id":274,
"Geo":"Aarhus"
}
Azure Event Hub (input)
Dataene flyder herfra videre til en såkaldt Azure Event Hub. Azure Event Hub’en er en mellemligende kø, der kan håndtere millioner af event beskeder i sekundet. Således samles data op, og gives videre i det tempo den øvrige processerings-pipeline i systemet kan tage fra med. Disse input data kaldes “eventhub-hinnerup-input” i T-SQL koden herunder.
Azure Stream Analytics
Den eneste data-pipeline vi har anvendt er Azure Stream Analytics. Her indsamles dataene i realtid og transformation, beregninger og analyse udføres efter nogle opstillede forretningsregler. Disse implementeres i T-SQL målrettet Stream Analytics området.
En række særlige kommandoer er tilgængelige man ikke finder i standard T-SQL, heriblandt “TumblingWindow” grupperingen vi gjorde brug af:
-- Input data transformation, calculations and analysis
WITH ProcessedData as (
SELECT
-- Telemetry device data
MAX(Celsius) MaxTemperature,
MIN(Celsius) MinTemperature,
AVG(Celsius) AvgTemperature,
MAX(Humidity) MaxHumidity,
MIN(Humidity) MinHumidity,
AVG(Humidity) AvgHumidity,
MAX(hPa/100) MaxPressure,
MIN(hPa/100) MinPressure,
AVG(hPa/100) AvgPressure,
-- Telemetry monitoring metrics
MAX(WiFi) WiFiConnectAttempts,
MAX(Mem) FreeMem,
-- Telemetry device info
location,
deviceId,
-- Time stamp
System.Timestamp AS Timestamp
FROM
[eventhub-hinnerup-input]
GROUP BY
TumblingWindow (second, 60),
deviceId,
location
)
-- Output data
SELECT * INTO [eventhub-hinnerup-output] FROM ProcessedData
Azure Event Hub (output)
De processerede data flyder nu ud via et Azure Event Hub output (“eventhub-hinnerup-output” i T-SQL koden herover). Disse kan udstilles via f.eks. WebSockets hvilket vi valgte. Der er mange andre muligheder, f.eks. kunne man også udstille dataene via en Azure API App (så et eksternt system som f.eks. en web-service også ville kunne tilgå dataene). Man kan godt vælge flere output former på en gang.
Azure Web App
Vi fandt en skabelon til et real-time dashboard, der kan konsumere Azure IoT data via WebSockets. Skabelonen kan hentes på GitHub her. Dette website deployede vi til en Azure Web App, og var således i rekord fart i luften med et automatisk opdaterende real-time dashboard der kan vise de indsamlede data.
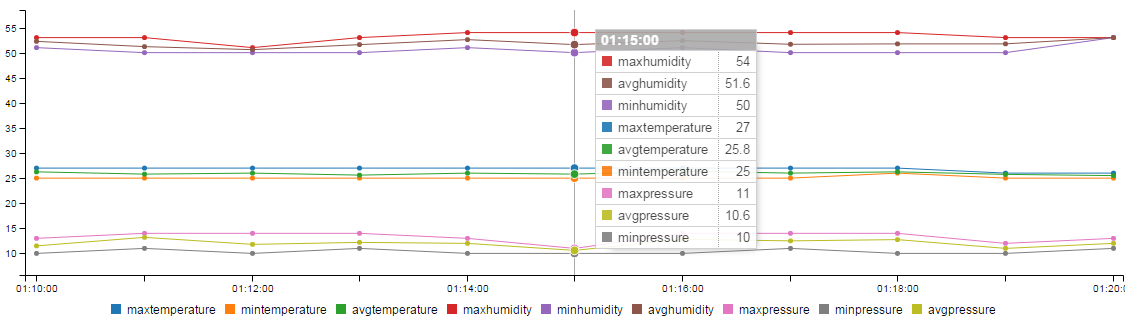
Klik på billedet for at se det i stort format.
Vi har godt nok kun én enhed tilknyttet systemet, men data fra alle tilknyttede enheder (som man kan specificere nærmere kriterier for i Azure portalen) ville i givet fald være blevet vist.
Afrunding
Her kan du se det samlede overblik i Azure portalen som vi endte ud med:
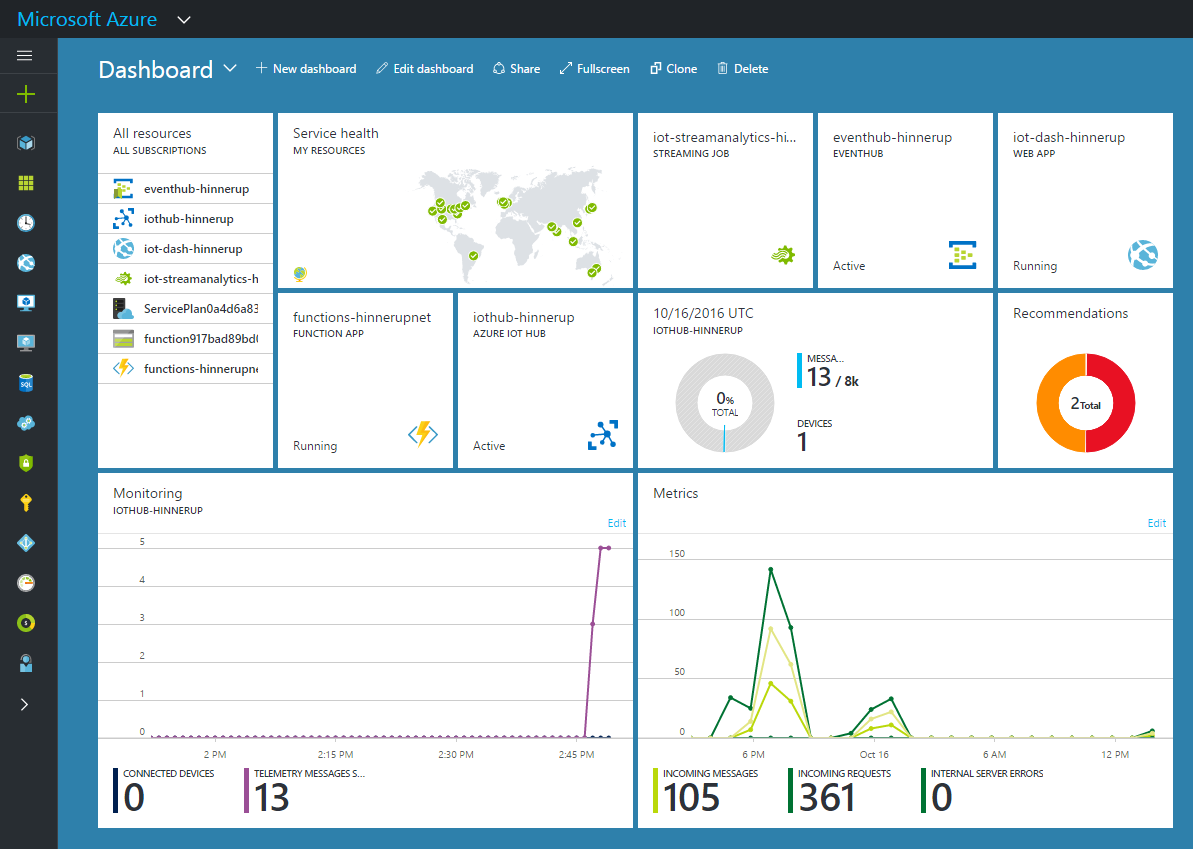
Klik på billedet for at se det i stort format.
Man kunne nemt have indsat storage, til f.eks. en MS SQL database og/eller til et data warehouse, og så derfra bygge videre med Azure HDInsights big-data analyse og videre endnu med kunstig intelligens processering. Man kunne også godt have koblet andre enheder på websitet (mobil browsere fx), ligesom de behandlede data godt ville kunne flyde over i et eksternt system via f.eks. en Azure API App løsning. Men, det går desværre nok en hel del ud over det tiltænkte omfang for denne demonstration. Indrømmet, da vi jo er nørder, var det meget svært at skære fra.
Til enterprise og produktionsbrug vil vi anbefale at der tages et kig på Microsoft PowerBI værktøjet til real-time dashboard visualiseringer og videre dataanalyse formål.
Som en afslutning er der vist blot tilbage at sige, at det var skægt og relativt nemt at lege med, og vi håber du har fundet artiklen interessant.





